If a database that should be backed up via SqlBak is not particularly large, then there is no need to set compression options in a specific way. It is recommended to use the default values.
The features below are designed to fine-tune compression for highly loaded systems and large databases.
How SqlBak Works
SqlBak works in the following way:
- Creates a backup file in a temporary folder
- Compresses the backup file in the temporary folder
- Deletes the backup file
- Repeats steps 1, 2, and 3 for all the databases
- Sends the compressed backup files to the selected destinations
- Deletes the compressed backup files from the temporary folder
- Repeats steps 5 and 6 for all compressed databases
Thus, there should be enough free space in a temporary folder that is used, to store the backup files and the compressed backup files at the same time. The temporary folder can be specified during backup job settings in the “Job Options” section.
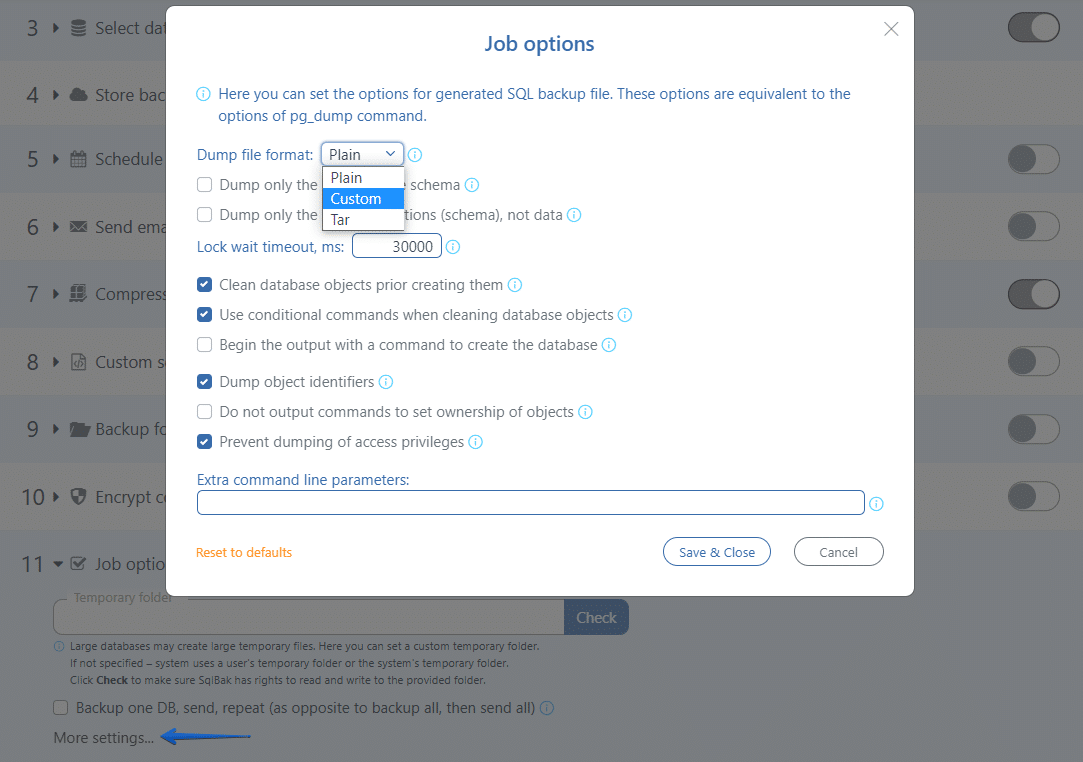
zip vs 7zip
During backup job settings, you can choose an archive format for your backups.
- zip – An archive will be created in the most common .zip format.
- zip (7zip-engine) – A zip archive will be created, but the 7zip utility will be used to create it. This allows you to use additional parameters of the 7zip utility.
- 7zip – A 7zip archive will be created via the 7zip utility. This option is faster and will compress the backups better than the first two options. You can also use advanced options for the 7zip utility.
If the zip (7zip-engine) or 7zip as archive format will be used, then for Windows and some Linux distributions the 7zip utility should be installed beforehand.
For large databases and heavily loaded systems – it is recommended to use 7zip as an archive format. This can significantly speed up a backup job and save space in backup storage.
Useful Parameters for 7zip
By default, 7zip uses the LZMA compression algorithm – this algorithm provides the highest compression ratio. However, the maximum number of threads that this algorithm can use is two. It takes a long time to compress large backups.
If you need to compress a large database, please specify the following additional parameters:
-m0=lzma2 -mmt=16
These parameters will force the use of the LZMA2 algorithm, which is almost as good as LZMA in terms of compression but can use up to 16 parallel threads (the number of threads is set by the -mmt parameter).
For MySQL and PostgreSQL (with plain backup format) it may be useful to use the BZip2 compression algorithm.
-m0=BZip2
BZip2 compresses text data faster than LZMA and LZMA2, but is slightly inferior in compression ratio.
Native Compression
For SQL Server and PostgreSQL, you can specify an option that will compress a backup right at the time of its creation – on the fly. In this case, you can generally disable the compression option during your backup job settings. As a rule, a job for which on-the-fly compression is used is faster than a job for which a compression option is used.
However, this method has a drawback – you cannot manage the compression ratio or the server resources that are used for compression.
For example, native backup compression for SQL Server can increase query execution time across the entire DBMS.
SQL Server
The SQL Server on-the-fly compression option can be enabled at the “Job options” section during your backup job settings.
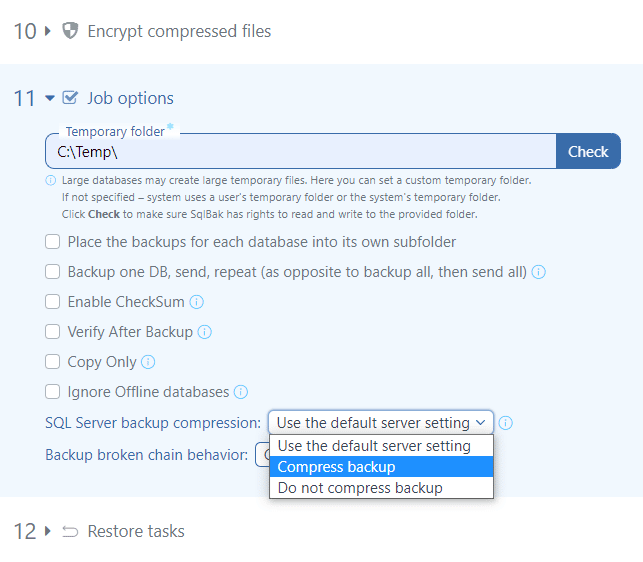
PostgreSQL
PostgreSQL on-the-fly compression can be enabled in the advanced job option section.