No matter what IT project you are creating, you will always need a sandbox for testing and development. If your product has a MySQL database, then you will need to create a database in a development environment.
You could manually create such a database and fill it with test data. However, if your product is in development, your database schema will change. For example, new tables will appear which will also need to be filled with test data. As a result, the process of maintaining a development database can become time-consuming.
The easiest way to create a development database is to sync it regularly with a production database. You will only need to configure such a synchronization process once, and the data in your development database will be as close to reality as possible.
In the following section, we will review production and development database synchronization methods.
- Creating a backup on the production database and performing restoration in the development environment:
- Setting up replication
Creating a backup on the production database and performing restoration in the development environment
Creating a production database dump and restoring it on a development MySQL Server is a great solution. You can run this process at night, and in the morning your test database will be just a day behind the production database.
In the following examples, the password is passed in command parameters for the sake of simplicity, but this is not a safe method. It is safer to move passwords to files and restrict read permissions for these files. You can do it for MySQL, mysqldump, and NcFTP.
Production database backup, FTP transfer and restoration on a development server
The easiest way to create MySQL backup is to use the mysqldump utility. This utility is included in MySQL Server. It is very easy to create a backup with it. To do this, run the following command on the production server:
mysqldump -u {user} -p{password} {database name} > backup.sql
Then transfer the dump to the development server. The easiest way to do this is via FTP.
ncftpput -u {ftp-user} -p {ftp-password} {development-ftp-end-point} / backup.sql
After you transfer the backup file it needs to be restored on the test server.
mysql -u {user} -p{ftp-user} < /var/ftp/backup.sql
Now we need to automate the process. This can be done using cron tasks. First of all, you need to create a task on the production server. To create a cron task enter:
crontab -e
As an example, we will create a backup every midnight. The FTP client of NcFTP supports piping, so you can combine the creation of a backup and uploading it to FTP.
0 0 * * * mysqldump -u {user} -p{password} {database name} | ncftpput -c -u {ftp-user}-p {ftp-password} --passive {ftp-end-point} backup.sql
A backup will be created every night and sent to the test server. To restore this backup, we need a cron task on the development server. It should lag behind the task that we created on the production server, allowing enough time to create and upload a backup. The restore command will look like this:
0 5 * * * mysql -u {user} -p{password} < /var/ftp/backup.sql
Now every morning our database in the test environment will sync with the production database.
The good thing about creating a backup and restoring is that you are probably already doing backups regularly, which means half of the work is done. You just need to pick up and restore the backup of your production base on the test server.
Database backup without temporary files
The mysqldump and MySQL commands support ––host option, which allows you to connect to a remote server. And since both mysqldump and MySQL support piping, you can dump the production database and restore it instantly in the development environment. Example:
mysqldump -h {production-host} -u {production-user} -p{production-password} -d {db-name} | sudo mysql -u {dev-user} -p{dev-password}
This is very convenient, but there is one significant drawback: if the production server and development server are not on the same subnet, then this method may not be applicable for security reasons. It is not recommended to keep the MySQL server port (3306) open for connection from the Internet.
Third-party backup and restore services
We have reviewed simplified examples of how you can copy a MySQL database. But in practice, simple solutions are often poorly applicable. The solution via cron and mysqldump lacks notifications in case of failure and minimal execution log. Bringing up FTP just for the sake of transferring the file may be uncalled for, and making it available over the Internet is not safe. Of course, you can write a more complex script and configure access through certificates, but this will require additional development and support. An alternative is third-party services that implement the entire process for you.
One of such services is SqlBak. SqlBak is a service for creating backups and sending them to cloud storage. It also has the ability to restore a database on another server after backup.
To synchronize production and development databases using SqlBak, you need to register on the website, and then install the SqlBak service on both servers and connect them to sqlbak.com. This can be done with one command.
curl -sSL https://sqlbak.com/download/linux/latest | sudo bash -s <secret-key>
You also need to establish a connection to the MySQL database on each server.
sudo sqlbak -ac -dt mysql -u root -p {mysql-password}
After that, both servers will appear on the Dashboard.

Now click the add job button and add a backup job. You will need to select databases which you need backup for and where to send it. The final step is to launch a restore after backup on another server.
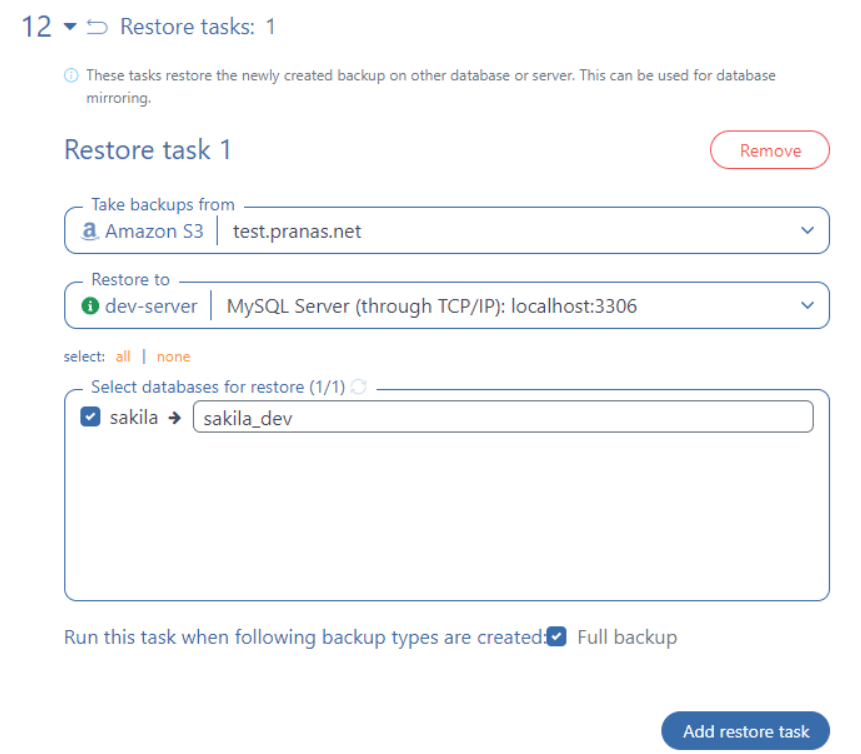
Then you can save and start the job. You will see a job log at the end of which there will be records of successful recoveries on the development server.
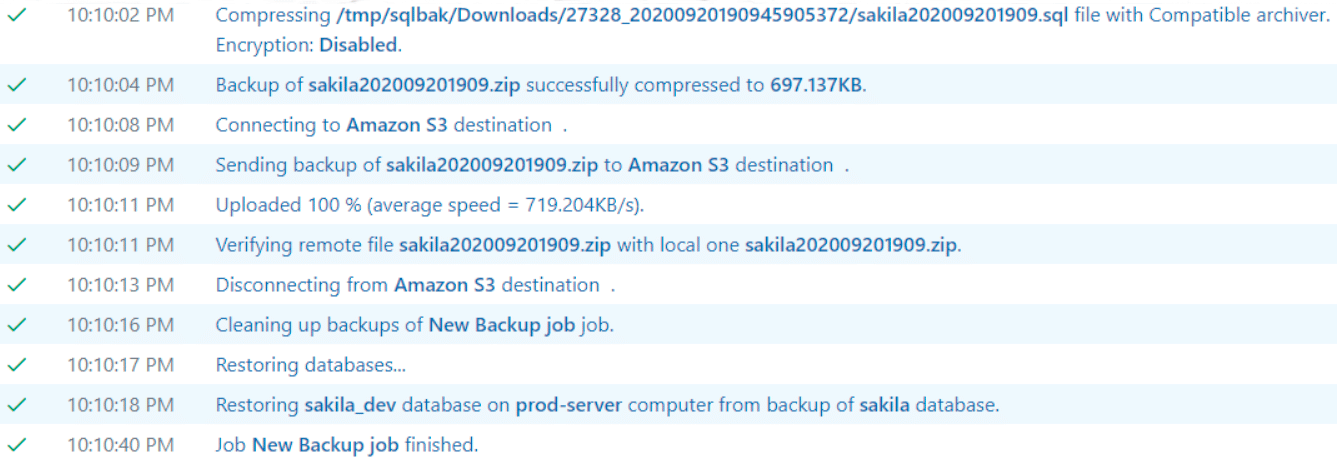
In addition to synchronizing production and development databases, SqlBak does an excellent job of doing regular backups. It supports various cloud storages and has many useful features, such as sending e-mail notifications, encryption and automatic deletion of outdated backups.
Replication
Another approach is to set up master-slave replication. The replication process will duplicate all transactions from the production server (master) on your development server (slave). The main disadvantage of replication is that the development server will be writable, which can lead to collisions.
Setting up replication for the entire server in MySQL is very straightforward. We provide simple instructions on how to do it below.
Master setup
First, you need to turn on bin logs on the master server. To do that, open file my.cnf.
vi /etc/mysql/my.cnf
If there is no my.cnf file in the given path, use sudo find / -iname my.cnf to find it.
Add or uncomment the following lines in the section [mysqld]:
[mysqld] server-id = 1 log_bin = /var/log/mysql/mysql-bin.log expire_logs_days = 10 max_binlog_size = 100M
We recommend creating a separate user on master when setting up replication. To do this, execute the SQL statement.
GRANT REPLICATION SLAVE ON *.* TO 'replication'@'{slave-ip-address}' IDENTIFIED BY '{password}';
Then restart MySQL for changes to take effect.
sudo service mysql restart
For the following steps, it is advisable to put the database in read-only mode. To do this, run
FLUSH TABLES WITH READ LOCK
Now run the SQL command, which will display binlog file status.
SHOW MASTER STATUS
You will see:
File: mysql-bin.001182 Position: 154 Binlog_Do_DB: Binlog_Ignore_DB:
Remember the highlighted values, they will come in handy when setting up a slave server.
Now you need to copy the data to the slave server. For this, we will create a dump of all databases
mysqldump -u root -p --all-databases > ~/dump.sql:
This completes your work on the master server. All that’s left is to unlock the tables.
UNLOCK TABLES;
Slave setup
Now we go to the dev server taking the dump.sql file with us. First of all, you also need to edit mysql.cnf on it.
Add or replace the following parameters in section [mysqld]:
server-id = 2 relay_log = /var/log/mysql/mysql-relay-bin relay_log_space_limit = 2000M
Save and restart MySQL instance for the changes to take effect:
sudo service mysql restart
Now we need to import dump.sql created on master server.
mysql -u root -p mysql < dump.sql
The last step is to specify a connection to the master server and start replication. For this, run the following SQL commands.
STOP SLAVE;
CHANGE MASTER TO
master_host='{master-ip}',
master_port=3306,
master_user='replication',
master_password='{password},
master_log_file='{bin-log-file-name}',
master_log_pos={bin-log-position};
START SLAVE;
Instead of orange values, substitute the values that were received on the master server as a result of command SHOW MASTER STATUS.
This completes the master-slave replication setup. Your development server will now be constantly in sync with the production server. However, due to the fact that the slave server is not in read-only mode, collisions may occur. For example, you can get unexpected errors while editing an entry that is being deleted at the same time on the production server. Also, in order to configure replication, you need a direct TCP\IP connection, which means that the production base must be available for external connections. This is considered unwise from a security point of view.
Conclusion
You can synchronize development and production databases in different ways. When choosing solutions, pay attention to your security requirements, the time you are willing to spend on support and your database size.
Hi,
Good job. This is exactly what I want to do. Can these steps be performed in Google Cloud (GCP)? Can you please throw more light?
Thank you
Hi Kay,
Could you please let us know, are you going to host databases on Google Cloud (GCP), or prefer to transfer backups via Google Cloud (GCP)?
Thank you!
Nice article. The process you have described in this post works with synchronizing/replication on two databases. What if in a scenario whereby you have several identical databases (local) and would like to do a 1 way sync of specific tables of the local databases to similar tables located on a single remote database. Any ideas?
Hi Ron2023,
When using mysqldump, you can specify table names after the database name as follows:
mysqldump -u username -p database_name table1 table2 > database_name.sqlDuring your backup job settings, in the Advanced Options, you can add the following parameter to exclude unnecessary tables:
--ignore-table=database_name.table_namePlease note that this parameter should be added separately for each table; you cannot specify multiple tables directly.
Regarding replication, you can add the following option to the my.ini file under the [mysqld] section:
replicate-do-table = database_name.table_nameThere are other methods available, and it’s worth noting that this topic is not entirely straightforward and has limitations, particularly with regard to foreign keys. For more comprehensive information, please refer to the following links:
https://dev.mysql.com/doc/refman/5.7/en/change-replication-filter.html
https://dev.mysql.com/doc/refman/5.7/en/replication-options-replica.html#option_mysqld_replicate-do-table
https://dev.mysql.com/doc/refman/5.7/en/replication-options-replica.html#option_mysqld_replicate-ignore-table