“Transaction was deadlocked” error occurs when two or more sessions are waiting to get a lock on a resource which has already locked by another session in the same blocking chain. As a result, none of the sessions can be completed and SQL Server has to intervene to solve this problem. It gets rid of the deadlock by automatically choosing one of the sessions as a victim and kills it allowing the other session to continue. In such case, the client receives the following error message:
Transaction (Process ID) was deadlocked on lock resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
and the killed session is rolled back. As a rule, the victim is the session that requires the least amount of overhead to rollback.
Why SQL Server Deadlocks Happen?
To understand how “Transaction (Process ID) was deadlocked on lock resources with another process and has been chosen as the deadlock victim. Rerun the transaction” error happens let’s consider a very simple example.
Let’s create two tables “t1” and “t2” containing only one integer column:
CREATE TABLE t1 (id int) CREATE TABLE t2 (id int)
and fill them with some data:
INSERT INTO t1 (id) SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 GO INSERT INTO t2 (id) SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3
Now, suppose we started a transaction that deletes rows with id=2 from t1:
BEGIN TRAN DELETE FROM t1 WHERE id = 2
Then, assume that the other transaction is going to delete the same rows from both tables:
BEGIN TRAN DELETE FROM t2 WHERE id = 2 DELETE FROM t1 WHERE id = 2
It needs to be waiting for the first transaction to complete and release table t1.
But, assume that the first transaction now deletes the same row from the second table:
DELETE FROM t2 WHERE id = 2
After executing this statement you should receive the following error message:
Transaction (Process ID) was deadlocked on lock resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
It is caused by a situation when the first transaction is waiting for the second one (to release t2) while the second transaction is also waiting the first (to release t1) one in the same time.
How to Analyze Deadlock Graphs
A deadlock graph is a block of information showing what resources and sessions are involved in a deadlock. It helps to understand why the deadlock happened.
Before SQL Servers 2008, in order to capture this information you had to set up a server-side tracing or enable trace flags and then wait while the deadlock occurs. Starting from SQL Server 2008 everything is much easier. You can retrieve a deadlock graphs retrospectively from the extended events “system_health” session. To do this, go to “Management” > “Extended Events” > “Sessions” > “system_health” > “package0.event_file” and click “View Target Data…”
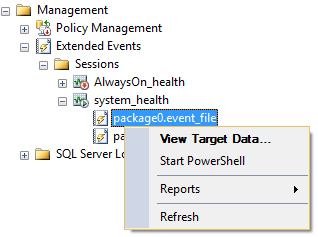
Thousands of events will be shown in the opened window. There you can find deadlock reports which marked as “xml_deadlock_report”. Let’s choose one we’ve just simulated
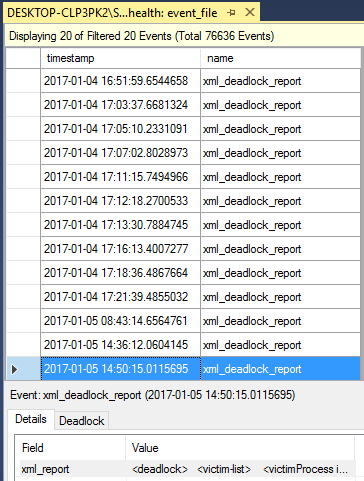
and look at its deadlock graph (in form of XML) details consisting of resources and processes sections.
Resources section displays the lists with all the resources which were involved in the deadlock:
It shows what processes were fighting over and what types of locks they were causing. It has two or more entries. Each entry has a description of the resource followed by the lists of the processes that held a lock or requested a lock on that resource. Locks in that section mainly will relate to a key, RID, a page or a table.
After the resources section let’s turn to the processes section to find out what those processes were doing.
Processes section displays the details of all the processes which were involved in the deadlock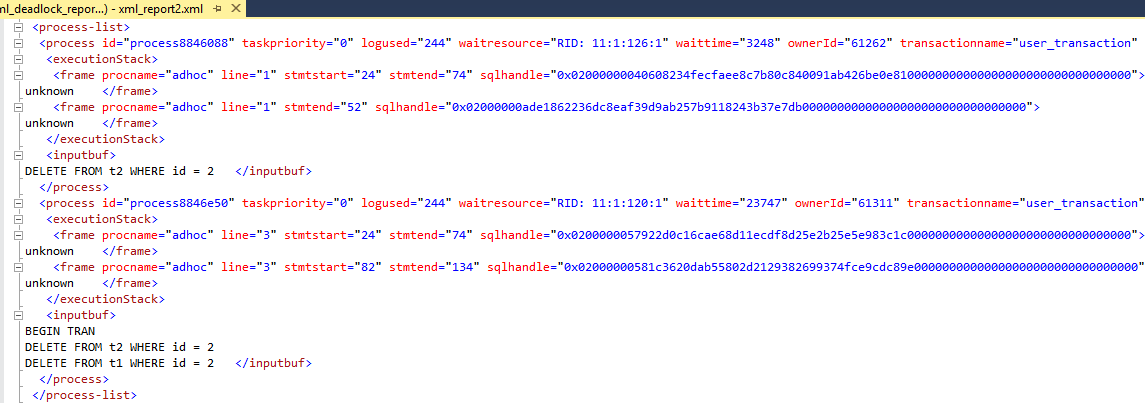
This section contains entries about the threads involved in the deadlock and provides such crucial information like host names, login names, isolation level, times, session settings and so on. But the most valuable information is the isolation level under which each query was running and the details about statement caused the deadlock.
How to Choose a Deadlock Victim
If you can’t avoid deadlocks, there is an option to specify which process should die when a deadlock occurs. SQL Server chooses a deadlock victim based on two factors: DEADLOCK_PRIORITY set for each session and the amount of work which SQL Server has to do in order to roll back the transaction.
The DEADLOCK_PRIORITY option can be set by a user to HIGH, NORMAL, LOW or to an integer value from -10 to 10. By default, DEADLOCK_PRIORITY is set to NORMAL (0). Use the following syntax to set deadlock priority:
SET DEADLOCK_PRIORITY { LOW | NORMAL | HIGH | <numeric-priority> | @deadlock_var | @deadlock_intvar } <numeric-priority> ::= { -10 | -9 | -8 | … | 0 | … | 8 | 9 | 10 }
For example, a session with NORMAL deadlock priority will be chosen as a deadlock victim if it involved in a deadlock chain with other sessions having deadlock priority set to HIGH or integer value greater than 0. And it will survive if the other sessions have LOW deadlock priority or its integer value less than zero.
LOW is equal to -5, NORMAL is the same as o, HIGH equals to 5. In other words, run the following commands to set a deadlock priority to NORMAL:
SET DEADLOCK_PRIORITY NORMAL; GO
or
SET DEADLOCK_PRIORITY 0; GO
To check the deadlock priority of the session you can use the following query:
SELECT session_id, DEADLOCK_PRIORITY FROM sys.dm_exec_sessions WHERE SESSION_ID = @@SPID
How to Avoid Deadlocks in SQL Server
As a developer, you need to design database modules in a way that minimizes risks of deadlocks. Here are some useful tips on how to do that:
Make sure the applications access all shared objects in the same order
Consider the following two applications (bad practice):
| APPLICATION 1 | APPLICATION 2 |
| 1. Begin Transaction | 1. Begin Transaction |
| 2. Update Part Table | 2. Update Supplier Table |
| 3. Update Supplier Table | 3. Update Part Table |
| 4. Commit Transaction | 4. Commit Transaction |
These two applications may deadlock frequently. If both are about to execute step 3, they may each end up blocked by the other, because they both need access to an object that the other application locked in step 2 and was not to release it till the end of the transaction.
Please see the following correction of the above example, changing the order of the statements (good practice):
| APPLICATION 1 | APPLICATION 2 |
| 1. Begin Transaction | 1. Begin Transaction |
| 2. Update Supplier Table | 2. Update Supplier Table |
| 3. Update Part Table | 3. Update Part Table |
| 4. Commit Transaction | 4. Commit Transaction |
It is a very good idea to define some programming policy that defines the order in which database objects and resources have to be accessed by the applications (also it is a good policy to release locks in the opposite order to that in which the applications locked them).
Keep transactions short and simple
Please consider the previous example:
the applications have two statements in a transaction (bad example)
| APPLICATION 1 | APPLICATION 2 |
| 1. Begin Transaction | 1. Begin Transaction |
| 2. Update Supplier | 2. Update Part |
| 5. Update Part | 5. Update Supplier |
| 6. Commit Transaction | 6. Commit Transaction |
Please consider the following changes in the above example (good example):
| APPLICATION 1 | APPLICATION 2 |
| 1. Begin Transaction | 1. Begin Transaction |
| 2. Update Supplier | 2. Update Part |
| 3. Commit Transaction | 3. Commit Transaction |
| 4. Begin Transaction | 4. Begin Transaction |
| 5. Update Part | 5. Update Supplier |
| 6. Commit Transaction | 6. Commit Transaction |
In this case you have everywhere one update at a time, thе transactions are very short, and there will be no deadlocks here at all.
Make sure the applications use the minimum necessary transaction isolation level.
The lower isolation level, the lower possibility of deadlocks (and the higher possibility of violation of data integrity, although).
For example, when the lowest isolation level possible (READ UNCOMMITTED) is used, there are no deadlocks at all. Although in this case you have to take special care of data integrity,
as READ UNCOMMITTED isolation level allows a transaction to read a table before another transaction finishes writing to the table (i.e. before the writing commits), and in this situation some data can be read before an update finishes, so you have to be careful about reading possibly outdated or inconsistent data.
Use “manual” lock/unlock possibilities to lock/unlock objects by yourself, not leaving it to the system, i.e. not using high level transaction isolation levels
Consider again the above two applications (bad practice):
| APPLICATION 1 | APPLICATION 2 |
| 1. Begin Transaction | 1. Begin Transaction |
| 2. Update Part Table | 2. Update Supplier Table |
| 3. Update Supplier Table | 3. Update Part Table |
| 4. Commit Transaction | 4. Commit Transaction |
Here the situation is prone to deadlocks, but if all of the ‘update’ statements are wrapped up with special lock/unlock procedures, then there will be no deadlocks.
Consider the applications changed this way (good practice).
| APPLICATION 1 | APPLICATION 2 |
| Begin Transaction | Begin Transaction |
| ‘Manual Lock’ of Part | ‘Manual Lock’ of Supplier |
| Update Part | Update Supplier |
| ‘Manual Release’ of Part | ‘Manual Release’ of Supplier |
| ‘Manual Lock’ of Supplier | ‘Manual Lock’ of Part |
| Update Supplier | Update Part |
| ‘Manual Release’ of Supplier | ‘Manual Release’ of Part |
| Commit Transaction | Commit Transaction |
To implement ‘Manual Lock’ use sp_getapplock procedure.
For ‘Manual Release’ usesp_releaseapplock procedure.
In the example above there will be no deadlocks (and no ‘lost updates’ etc) even using the lowest transaction isolation level, as each transaction do not ask for access to another object before releasing the previous one.
In case Repeatable read or Serializable isolation levels are required, and two applications use the same database object very frequently, use UPDLOCK hint
Consider the following two transactions (bad practice):
| APPLICATION 1 | APPLICATION 2 |
| 1. Begin Transaction | 1. Begin Transaction |
|
2. Read Part table (S-lock #1 is set by the Read) |
2. Read Part table (S-lock #2 is set by the Read) |
|
3. Change structure of Part table (waiting for S-lock #2 release) |
3. Change structure of Part table (waiting for S-lock #1 release) |
| 4. Commit Transaction | 4. Commit Transaction |
Here are the two transactions just checking some data up before changing them
(e.g. counting a number of records of a table before inserting a new record in it).
On step 2 both transactions apply S-lock to the same database object and then on step 3 they both wait for release of the S-locks for changing something in the structure of the object (e.g. inserting a row to the table).
Please see the changes in the two transactions (good practice):
| APPLICATION 1 | APPLICATION 2 |
| 1. Begin Transaction | 1. Begin Transaction |
|
2. Select Part table with UPDLOCK optimizer hint |
2. Select Part table with UPDLOCK optimizer hint |
|
3. Access Part table |
3. Access Part table |
| 4. Commit Transaction | 4. Commit Transaction |
The advice is to start all relevant transactions with SELECT statement with UPDLOCK optimizer hint for making the two applications to deal with the same database object one after another in turn:
SELECT * FROM Part WITH (UPDLOCK)
Other advices on how to avoid deadlocks in SQL Server
There are also other general advices related to the matter, such as
- have normalized database design,
- use bound connections and sessions,
- reduce lock time (e.g. don’t allow users input during transactions),
- avoid cursors,
- use row versioning-based Isolation levels,
- use ROWLOCK optimizer hint,
etc.
