 Are you sure you can restore your database with the help of backups with minimal loss? Do you restore your data regularly? Probably many SQL Server users don’t even think of it until it strikes them. So ask yourself yet another question – What should I do about my backup to make sure I can restore it with minimal loss should a disaster occur? To put it shortly – You need to check the health of your SQL Server database regularly. Read on to find out how it’s done. Read More
Are you sure you can restore your database with the help of backups with minimal loss? Do you restore your data regularly? Probably many SQL Server users don’t even think of it until it strikes them. So ask yourself yet another question – What should I do about my backup to make sure I can restore it with minimal loss should a disaster occur? To put it shortly – You need to check the health of your SQL Server database regularly. Read on to find out how it’s done. Read More
Author: Alexandr Omelchenko
File Backups
SQL Server allows to make backups and restore not only the entire database but also a single filegroup or even a separate file. This is called a file backup. This type of backup contains all data from one or more files or filegroups.
File backups are often used to increase the recovery process speed by restoring only damaged files, without restoring the rest of the database, if necessary. Assume there is a database that contains several files. Each file is stored on a separate disk and suddenly one disk fails. In this case the recovery process will not take more time because there is no need to restore the entire database, it will be enough to restore only the file from the failed disk. Read More
Point-in-time recovery
Point-in-time recovery allows to restore a database into a state it was in any point of time. This type of recovery is applicable only to databases that run under the full or bulk-logged recovery model. If the database runs under the bulk-logged recovery model and transaction log backup contains bulk-logged changes, the recovery to a point-in-time is not possible.
To understand how point-in-time recovery works let’s review the use case with a sample database (under the full recovery model) where a full backup is made every 24 hours and a differential database backup that is created every six hours, and transaction log backups are created every hour. Please see the picture below: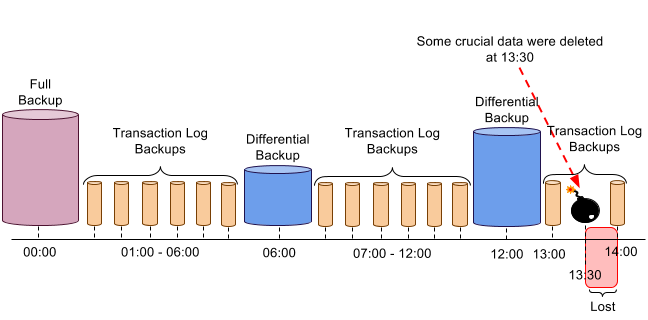
Read More
Violation of … constraint ‘…’. Cannot insert duplicate key in object ‘…’ (Msg 2627)
SQL Server’s error “Violation of … constraint ‘…’. Cannot insert duplicate key in object ‘…’” can appear when a user tries to insert a non-unique value into a table’s unique column such as the primary key. Look at the following syntax:
CREATE TABLE Table_1 (ID INT NOT NULL PRIMARY KEY, NAME VARCHAR(10) NOT NULL, AGE date);
Invalid filegroup ‘…’ specified (Msg 1921)
“Invalid filegroup ‘…’ specified.” error can appear in the case when the name of Filegroup where the new Table_1 will be stored is invalid. Look at the syntax bellow:
CREATE TABLE Table_1 (Column1 int primary key, Column2 char(8)) ON [SecondaryFilegroup];
CREATE DATABASE failed. Some file names listed could not be created (Msg 1802)
The error “CREATE DATABASE failed. Some file names listed could not be created. Check related errors.” can occur when the user tries to create a database with file names specified. To understand when this error can appear and how to avoid it, let’s consider the following syntax:
CREATE DATABASE Adventureworks ON PRIMARY ( NAME = Adventureworks_Data, FILENAME = 'Adventureworks_Data.mdf', SIZE = 0, MAXSIZE = 30, FILEGROWTH = 10% ) LOG ON ( NAME = Adventureworks_Log, FILENAME = 'Adventureworks_Log.ldf', SIZE = 3MB, MAXSIZE = 20MB, FILEGROWTH = 3MB ); GO
Transaction (Process ID) was deadlocked on lock resources with another process and has been chosen as the deadlock victim (Msg 1205)
“Transaction was deadlocked” error occurs when two or more sessions are waiting to get a lock on a resource which has already locked by another session in the same blocking chain. As a result, none of the sessions can be completed and SQL Server has to intervene to solve this problem. It gets rid of the deadlock by automatically choosing one of the sessions as a victim and kills it allowing the other session to continue. In such case, the client receives the following error message:
Transaction (Process ID) was deadlocked on lock resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
and the killed session is rolled back. As a rule, the victim is the session that requires the least amount of overhead to rollback. Read More
Database ‘Adventureworks’ cannot be opened. It is in the middle of a restore (Msg 927)
To understand how to avoid “Database ‘Adventureworks’ cannot be opened. It is in the middle of a restore” error let’s consider the following example:
Assume, in the database some crucial data were deleted, and the restore operation was started
RESTORE DATABASE Adventureworks FROM DISK = 'Adventureworks_full.bak' WITH NORECOVERY, REPLACE
Database ‘Adventureworks’ does not exist (Msg 911)
“Database ‘Adventureworks’ does not exist. Make sure that the name is entered correctly” this can occur if there is a mistake in the name of the database. Assume that there is a need to run the database “Adventureworks”. The next syntax was used to issue the database:
USE Advantureworks
Unknown object type ‘…’ used in a CREATE, DROP, or ALTER statement (Msg 343)
Let’s consider the error “Unknown object type ‘…’ used in a CREATE, DROP, or ALTER statement” in the following example:
There is a need to add one more column “Column4” in the table “Table_1” which is located in the database “Adventureworks”. To execute this operation has been used the next syntax
ALTER Table_1 ADD Column4 INT;
